C Compilation: From Code to Binary
A straightforward guide to the C compilation process. From your code to the final binary, we'll walk through each step with examples to make it easy to follow.
So, I’ve noticed that most people tend to steer clear of this topic (and I don’t blame them, my university has its own squad of “talented individuals” who’d rather take a nap than deal with this). And that’s exactly why I decided to write about it, so this can be the one-stop guide for all the Googlers out there. Enough yapping, let’s get into it!
What I’ll be covering:
The Whole C Compilation Process: (Don’t worry, other languages follow a similar model or maybe not, so you’ll catch on. Probably.) Plus, let’s be real - C was everyone’s first programming crush. It was a little messy at first, but it helped you grow (just like your first awkward relationship).
Now, I’m going to do this a bit differently. When I was learning, I had a hard time wrapping my head around what was happening in each phase of compilation. So, I’m going to walk you through it with some real examples from an actual program. Let’s roll!
The C Compilation Process
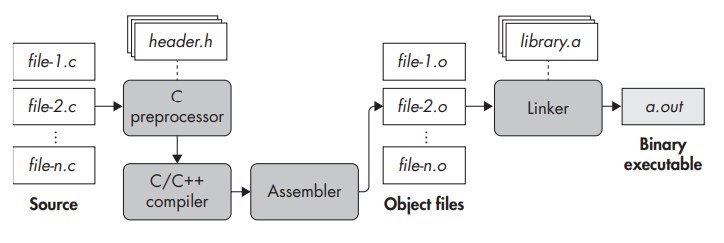
The C Compilation Process
So, in a nutshell, compilation is the process of turning your human-readable source code (yes, that lovely C/C++ code you wrote) into machine code that your computer can actually run. Sounds easy, right? Well, it’s not as simple as just pressing a button, but I’ll make it sound that way.
Compiling C code involves four phases, one of which (awkwardly enough) is also called compilation, just like the full compilation process. The phases are preprocessing, compilation, assembly, and linking
1. Preprocessing Phase:
The journey starts with your source files (file-1.c through file-n.c). Sure, you can get by with just one source file, but let’s be real, big projects usually involve many files. Why? Because if one file changes, you only need to recompile that one, not the entire project. It’s like editing a single paragraph in your 20-page essay rather than redoing the whole thing.
Now, your C source files are full of macros (#define) and #include directives (#include) (for including header files, those .h files that seem to always cause confusion). The preprocessing phase expands these directives, so what you’re left with is clean, pure C code. It’s kind of like decluttering your room before your parents visit: you want to get rid of the mess before anyone sees it.
Let’s make this concrete with an example! Here’s a basic program using gcc (the default compiler for most Linux users, unless you’re using MSVC, but we’ll try not to judge you too harshly). Here’s the source file:
1
2
3
4
5
6
7
8
9
#include <stdio.h>
#define FORMAT_STRING "%s"
#define MESSAGE "I don't know what I'm doing : )"
int main(int argc, char const *argv[])
{
printf(FORMAT_STRING, MESSAGE);
return 0;
}
Now by default, after the preprocessing phase, what happens next? gcc runs through all the compilation stages, but if you only want to see the output after preprocessing, you can stop it with the following command:
gcc -E -P
Where:
-Etells gcc to stop after preprocessing (because, let’s be honest, we don’t want to get overwhelmed and quit halfway through ).-Ptells it to skip the debugging info, so the output is cleaner.
gcc -E -P compilation_ex.c
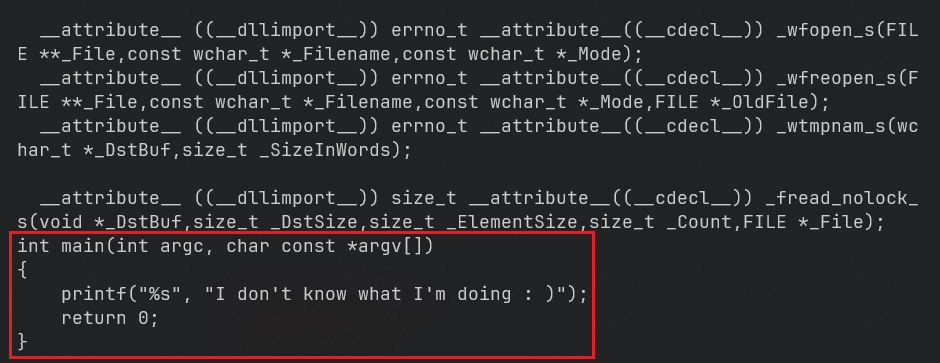
Preprocessor output
So, after the preprocessing phase, you end up with a huge mess of declarations and code. But, if you scroll to the end, you’ll finally reach the main function as you can see above.
Now, let’s take a step back and understand what’s happening. The stdio.h header has been fully included, which means all its type definitions, global variables, and function prototypes are effectively “copied” into your source file. It’s like if you invited all your friends to the party, and now they’re all hanging out in your living room (whether you like it or not).
And since this happens for every #include directive, the output from the preprocessor can get pretty verbose.
But wait, there’s more! The preprocessor also fully expands any macros you’ve defined with #define. So, in this example, both arguments to printf (those FORMAT_STRING and MESSAGE variables) are evaluated and replaced by the constant strings they represent. Some really cool stuff !
2. The Compilation Phase:
Alright, now that the preprocessor has done its thing (and left us with a bloated pile of code that barely makes sense), we move on to the compilation phase. This is where the preprocessed code is translated into assembly language. Yep, assembly, the scary, cryptic stuff your professor probably glanced over while saying, “Don’t worry, you’ll never have to write this by hand.” Lucky for us.
Most compilers, like gcc, also perform some heavy optimization at this stage. These optimizations can range from “I’ll do absolutely nothing” (-O0) to “Let me squeeze every drop of performance out of this code, even if it confuses the living daylights out of you” (-O3). And for those of us who want to really push the limits of sanity and performance, there’s always -Ofast, where the compiler takes all the shortcuts and hopes it doesn’t break anything. These optimizations can make a huge difference when analyzing the assembly later, because why not make things harder for yourself?
Pause for Thought: Why Assembly, Not Machine Code?
Here’s the question that might’ve crossed your mind: “Why does the compiler spit out assembly language instead of going straight to machine code?” I mean, wouldn’t that save time? Sure, but this approach actually makes a lot of sense when you think about it (which, admittedly, took me a while).
There are tons of compiled languages out there - C, C++, Go, Haskell, and even languages most of us have never touched (looking at you, Objective-C). Writing a compiler that directly generates machine code for each of these would be a nightmare.
Instead, compilers generate assembly code, a nice middle ground that’s challenging but not outright soul-crushing. From there, a dedicated assembler can handle translating it to machine code. Efficient, right? Well, except for the part where you’re stuck reading assembly. That’s on you.
The output of this phase is assembly code, which is sort of human-readable. Symbols and function names are preserved, so it’s not just raw numbers flying at you. To get a peek at the assembly code, you can tell gcc to stop after this phase by using the -S flag. This saves the assembly code to a .s file. If you want it in Intel syntax instead of the default AT&T syntax (because who actually likes AT&T syntax?), you can add -masm=intel.
gcc -S -masm=intel source_file.c
Now you’ve got yourself an assembly file. What does it look like? Well, something like this:
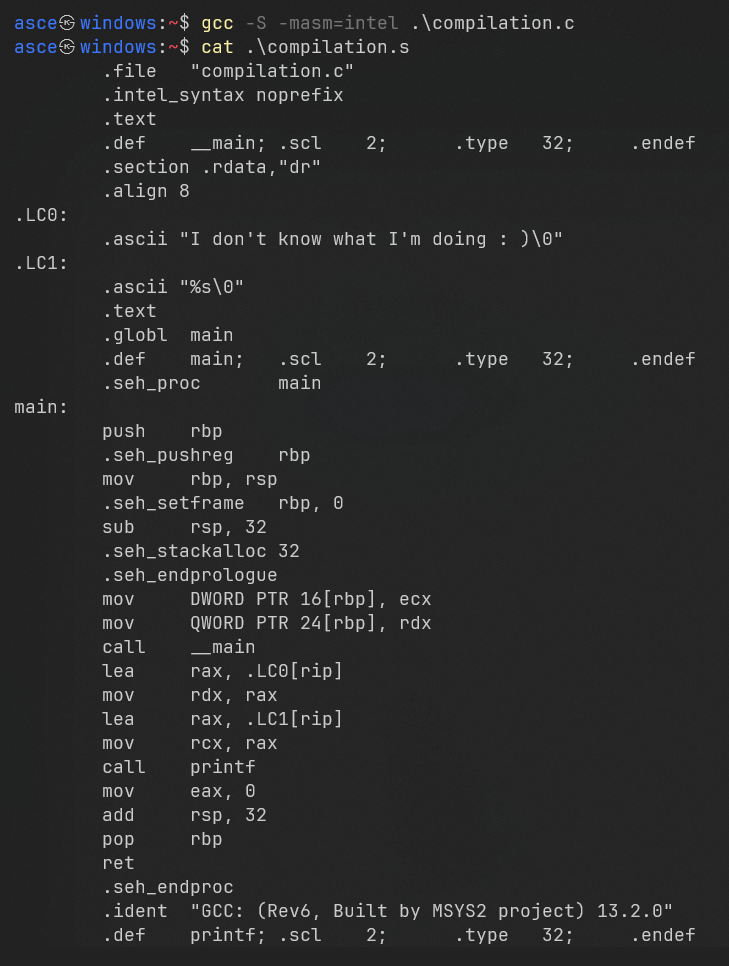
Assembly code for our program
Don’t worry, it might look intimidating at first, but assembly code isn’t all that bad. (Okay, maybe this one is, but let’s pretend for a moment.). Assembly is actually relatively easy to read, if you squint and pretend you understand what’s happening.
The good news? Symbols and functions are preserved, so instead of staring at raw memory addresses, you’ll see symbolic names like LC0 for a nameless string like “I don’t know what I’m doing :) “ and LC1 for format_string.
You’ll also notice explicit labels, like main, for the functions in your code. This makes it slightly less terrifying… for now. But if you’re ever unlucky enough to deal with stripped binaries, say goodbye to those nice symbols. At that point, it’s just you, a sea of raw addresses, and the slow realization that maybe you should’ve taken up gardening instead.
3. The Assembly Phase
Alright, now we’re getting closer to the real deal. In the assembly phase, we finally generate actual machine code, the kind your processor understands (unlike you, staring at it in utter confusion).
What’s Happening Here ?
The input to this phase is the set of assembly language files produced during the compilation phase. The output? Object files, sometimes called modules. These object files contain machine instructions that, in theory, your CPU could execute, but not yet, because they still have unresolved references (e.g., function calls to external libraries or other object files). Think of it like this: I know that I’ve used printf from stdio.h, you know that you’ve used printf from stdio.h but our object file is still clueless about where the hell printf actually came from.
So it means we’re still missing a few pieces before we have a fully functional, ready to run executable.
Now, typically each source file translates to one assembly file, which then corresponds to one object file. Think of it like assembling a jigsaw puzzle, each piece is self-contained, but you need to put them together before seeing the full picture.
To generate an object file, you pass the -c flag to gcc:
gcc -c compilation.c

Generating object files
At this point, you might be wondering: How do I even know this is an object file? Well, you can confirm this using the file utility:
file compilation.o

File command output
Alright, I’m Gonna Break it Down, well, you hired me for this, right? Lol !
ELF 64-bit: This tells us that the file follows the ELF (Executable and Linkable Format) specification, which is the standard format for binary executables on Linux.
LSB: This stands for Least Significant Byte first (little-endian format). Essentially, when storing multi-byte data in memory, the smallest part (least significant byte) comes first.
Relocatable: This tells the linker that the functions and variables are not bound to any specific address yet. Instead, the addresses are still symbols.
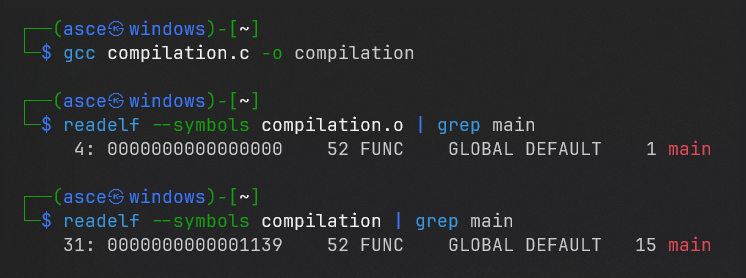
Comparing symbols of an object file and executable
See? The relocatable object file has this main symbol associated with the 00000000 address. The executable file has the same main symbol associated with real address.
So what happens, after the compiler and assembler generate the relocatable object file, the data start at address 0. It’s the linker then kicks in and relocates these sections by associating each with a location with in memory.
x86-64: This specifies the architecture of the machine for which the object file is intended. x86-64 is the 64-bit version of the x86 architecture, widely used in modern Intel and AMD processors.
Version 1 (SYSV): This refers to the System V ABI (Application Binary Interface), which is a standard for how compiled programs interact with the operating system and hardware. It’s essentially a set of conventions that ensures your program works with the operating system’s kernel and other programs.
Not Stripped: This means the object file still contains debugging info things like function names, variable names, and other human-readable goodies. Basically, it’s the cheat sheet for debugging your program.
If it were stripped, this debugging information would be removed, leaving only the machine code, making the file smaller and more difficult to debug or reverse engineer.
Wait, did you even know that there are multiple ways to store data in memory ?
Yeah, computers don’t like keeping things simple. When dealing with multi-byte data, systems follow different storage formats:
- Big-endian (Most Significant Byte first)
- Little-endian (Least Significant Byte first)
- Middle-endian (a.k.a. PDP-endian, Mixed-endian, or Why-Would-You-Do-This-endian ?)
Most modern CPUs, like x86, use little-endian, while some architectures (like Motorola PowerPC or network protocols) stick with big-endian. But if you’re really unlucky, you might encounter middle-endian, an unholy mutation found in some older architectures (like PDP-11).
Example Time:
Let’s say we need to store 0xDEADBEEF ( a 4 byte value). Why ? Why not !
Big-Endian (MSB first)
Data is stored in memory exactly as it’s written (because humans like things that make sense, right?). The Most Significant Byte (MSB) is placed at the lowest memory address, followed by the rest of the bytes in the order they appear.

Big Endian Representation
Pretty nice and logical. No surprises.
Little-Endian (LSB first)
Little-endian is when the Least Significant Byte (LSB) gets placed at the lowest memory address, and the rest follow in reverse order. It’s like reading a book backwards, why? Because in many cases, the LSB is the first byte you need to work with, so it’s quicker to access it first.

Little Endian Representation
See? It’s the same number, just backwards. If you’re ever poking around in memory dumps or dealing with low-level data, you’ll realize that little-endian makes everything look completely reversed.
Middle-Endian (WTF IS THIS ?)
Now for the grand finale, middle-endian. Just when you thought things couldn’t get any weirder? Well here we are.
Middle-endian is what happens when a system decides to store parts of a value in big-endian and other parts in little-endian. It’s like someone couldn’t decide which endianness to use and just… mixed them.

Middle Endian Representation
This format appeared in systems like the PDP-11, where 32-bit numbers were stored as two 16-bit words, but within those words, the bytes were in little-endian. For example, storing JOHN as a 32-bit value would end up as O J N H in memory.
One thing for sure, it would make a pretty cool CTF challenge xD.
Doubt Clearing Session
Now some of you might think that big-endian seems more “human-friendly” since it matches the way we write numbers, so why won’t we use it for modern processors ? Let me cook up an answer for you !
One of the reasons (from my extensive “stare-at-the-screen-while-banging-my-head” moments, aka binary exploitation and reversing, and looking at hex dumps) is that little endian requires less work to perform operations.
For example:
Let’s take a 64-bit number 0x1234567890ABCDEF. The memory layout would look like this:
Little Endian:

Little Endian Representation
Now if we only need the last 32 bits (0x90ABCDEF), they are already at the beginning ( starting at 0x100 ). Meaning, you start at 0x100, read 4 bytes and reverse it. Noticed, this way the base address remains the same for all the data sizes (byte, word, dword, qword). You can read it directly, no need for shifting, and masking.
Big Endian:

Big Endian Representation
In big-endian, to extract the last 32 bits (0x90ABCDEF), you need to apply a mask (AND 0xFFFFFFFF). The base address changes depending on the data size, so different data sizes need different memory accesses.
Final Note: Endianness Isn’t That Deep
After doing some deep research (and by that, I mean staring at my screen until my brain melted), I realized, there’s may not be real advantage to either endianness, except for that middle-endian. Seriously, who thought that was a good idea? : |
We use big-endian for network protocols (like IP addresses), but little-endian dominates modern computing purely due to historical reasons (thanks, Intel).
What really matters isn’t which format is better, but that we all agree on one format for consistency and interoperability. Because, let’s be honest, if half the world used little-endian and the other half used big-endian, debugging cross-platform software would be an absolute nightmare.
4. Linking Phase
So, we’ve reached the linking phase, the final stage in the compilation process, where all those lonely object files finally come together and form a single executable. Think of the linker as the matchmaker who unites these files into a beautiful relationship (without the drama).
In modern systems, the linking phase sometimes includes an additional optimization pass called Link-Time Optimization (LTO). Because, really, why not make the final product even more efficient, right?
Now, unsurprisingly, the program that does all this matchmaking is called the linker, or link editor. It’s usually a separate tool from the compiler, which works upon the compiler’s output. Think of the compiler as your personal trainer and the linker as the coach who brings all the pieces together to help you win the championship.
As mentioned earlier, object files are relocatable because they are compiled independently from each other. This means the compiler can’t assume that an object will end up at a specific address. Each object file contains symbolic references aka, placeholders for memory addresses of functions and variables. The linker’s job is to resolve these references by finding the actual addresses and placing them in the right spots. So when your code calls a function, the linker ensures the function exists and is placed correctly. It’s like the linker’s a GPS, ensuring everything is where it needs to be.
One thing to note: references to libraries may not be fully resolved during the linking phase, especially with dynamic linking. This is called lazy resolution in Linux. Symbol references from dynamic libraries aren’t resolved until they’re actually called for the first time, which uses structures like the PLT (Procedure Linkage Table) and GOT (Global Offset Table), more to PLT and GOT for some other day ; ). Anyways, the linker essentially says, “I’ll get to it later.”
With dynamic libraries (like .so files), the linker leaves placeholders in the executable, noting that it will need them later. The actual resolution is handled by the dynamic runtime linker (like ld-linux-x86-64.so.2 which is 64-bit version, there’s a 32-bit one too). I call it the dynamic runtime linker to distinguish it from the dynamic linking process, but in reality, it’s just an interpreter program that resolves symbolic references when the dynamically compiled executable is run.
Also one cool thing, Dynamic libraries are shared across all programs on the system, so they only need to be loaded into memory once. Any binary that needs them just borrows the same copy. Pretty efficient, right?
On the other hand, if you’re using static libraries (like .a files), the linker grabs the relevant parts and incorporates them directly into your executable. No waiting around here, every reference is resolved at the linking stage, and everything is included in the final product.
Most compilers, including GCC, automatically call the linker at the end of the compilation process. To produce a complete binary executable, you can simply call gcc without any special switches. By default, the executable is called a.out, but you can override this by using the -o switch in GCC.
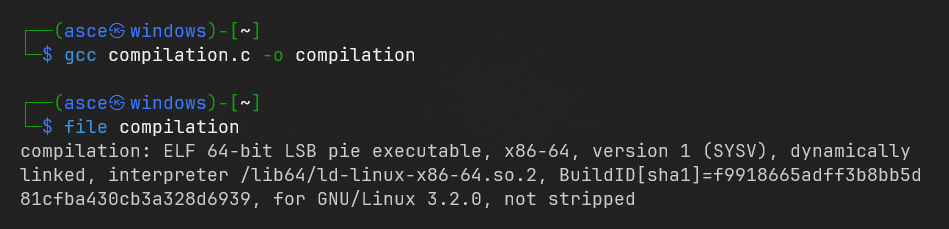
Compiling our C Program with gcc
Finally, when you run the file command on your executable, it will tell you that it’s an ELF 64-bit LSB executable, rather than a relocatable file like the ones you saw at the end of the assembly phase. It’ll also say the file is dynamically linked, meaning it uses shared libraries, and give you the name of the dynamic linker that will resolve the final dependencies when the executable is loaded into memory. When you run the binary (e.g., ./a.out), you’ll see the expected output, which proves that the linker did its job and everything’s working as it should.
Output of our C Program
References:
- Practical Binary Analysis - A very great book !
- Guide to Object File Linking
- Advantage of little-endian, seemingly there’s none